翻書的智者:解決 LLM 幻覺的檢索增強生成技術 (Retrieval Augmented Generation - RAG)
2024-03-30 Sat

圖片來源:使用 DALL E 製作機器人看到彩色的幻覺圖
LLM 的幻覺
大型語言模型(LLM)雖然能生成流暢文字,但完成訓練後,其知識就固定下來,難以反映最新的資訊或事實。在準確性上,處理專業知識或需高準確度場景時,可能出現不準確或偏頗訊息,甚至被稱為幻覺 (Hallucination)。另外 LLM 訓練及運行耗費巨大計算資源這對於許多機構和個人來說,都是一大負擔。
為了解決這些問題,結合檢索增強生成 - Retrieval Augmented Generation(以下簡稱 RAG 表示),透過檢索資料來輔助生成過程提高了回答的準確性與降低資源使用率。
翻書找答案的 RAG
究竟什麼是 RAG(Retrieval Augmented Generation)呢?我們可以將他比喻為一位經驗豐富的顧問,他在面對客戶提出的複雜問題時,不僅依靠自己多年積累的知識和經驗來提供解答,也會積極地翻閱書籍、檢索資料庫,以確保能夠提供最準確的答案。
在理解 RAG 前可以先知道以下概念
- Vector in RAG
- Embedding
- Retrieval
Vector in RAG
向量表示事物
向量在 RAG 當中我們可以想像地球是一個巨大的資料庫,每個地點都能透過一對特定的數字 (經度和緯度) 來確定其在這本「資料庫」中的位置。
這對數字就像是該地點的「向量」,不僅指出其確切位置,還隱含了更多資訊,如相對其他國家的位置、氣候區域等。以台灣這個實體物件為例,它的向量可以表示為(121.5, 25.0),這組向量可以表示台灣的經度與緯度的數值。
添加更多向量表示事物
如果我們選擇「經濟發展指數」作為第三個維度,而這個指數可以是任意衡量台灣經濟狀況的數字(比如人均 GDP)。假設台灣的人均 GDP 為32756美元,那麼我們可以將台灣這個地點的向量表示為(121, 25, 32756)。這樣的向量不僅定位了台灣的地理位置,還給出了其經濟發展的一個指數。
接下來與其他國家比較以日本為例子,日本的維度是日本轉換成向量即是 (138,36, 33911),而泰國的向量為 (100,15,7274),儘管日本與泰國皆是在亞洲區域與台灣位置相近,在這個三維空間模型中,台灣和日本可以被視為相對靠近的兩個點,因為它們在地理位置上接近,同時在經濟規模上也比較相近。
這種方式將「台灣」這個概念映射為一個包含三個維度的向量,使得我們能夠在更加豐富的維度上描述和理解台灣。 在自然語言處理中使用多維向量來捕捉單詞或句子的多重含義和特徵。
Embedding

圖片來源:Embeddings: Meaning, Examples and How To Compute
在數學領域,「嵌入」指的是將一個數學結構通過某種映射關係嵌入到另一種數學結構之中。換句話說就像文字轉換成向量形式。
這種轉換不僅適用於文字,還廣泛應用於用戶資料、物品資料、圖片結構以及詞彙等不同實體的嵌入,如用戶嵌入(User Embedding)、是指將用戶的資訊和行為轉化為一個向量,這個向量反映了用戶的偏好、興趣和其他特性。例如,一個用戶可能喜歡觀看動作電影、閱讀科幻小說,並且經常在週末進行戶外活動。用戶嵌入會將這些訊息綜合起來,形成一個密集的向量,這個向量可以在推薦系統中用來預測用戶對未知物品的偏好。物品嵌入則是將物品(例如電影、書籍、商品等)的特徵轉化為向量。這個向量包含了關於物品的重要訊息,比如類別、風格、品牌或其他屬性。
透過嵌入技術,"哈利波特"這個詞就不再只是一系列無意義的文字,而是變成了一個能夠表達其語義關係和特徵的數字向量。這種向量的表示讓機器能夠在處理自然語言的複雜任務,有了更深層次的「理解」。
下面透過 Embedding Projector 視覺化技術將 Word2vec 呈現在三維空間當中,這裡可以看到 perl 與 Java 和 Javascript 有較近的距離 (畢竟都是程式語言)

另外像是 leg 和 knee 和 arm 有較近的距離

圖片來源 : tensorflow projector
Retrieval
Retrieval 指的是一種處理過程,旨在從一個廣闊且結構化的資料中,根據特定的查詢條件或需求,檢索並提取出相關資訊。以下用傳統檢索方式和向量檢索方式來分類
- 傳統的檢索方法
- 布林檢索:這是一種基於布林邏輯(AND、OR、NOT)來過濾資料的方法,根據用戶查詢中的關鍵字和布林運算符來找到匹配的文檔。
- 關鍵詞檢索:這種方法通過 match 查詢中的關鍵詞與資料中檢索,並不一定需要將資料轉化為向量形式。
- 向量檢索
它涉及將查詢和資料集中的內容轉換成高維向量,並通過計算向量之間的相似度來進行檢索。這種方法特別適用於需要理解查詢和資料之間複雜語義關係的場景,Retrieval 不僅包括傳統的文本檢索,還擴展到了語義檢索、多模態檢索等等,這些領域要求系統不僅能理解查詢的字面意義,還能捕捉到其語義上的細微差異,並從多種類型的資料源中提取出有用的資訊。
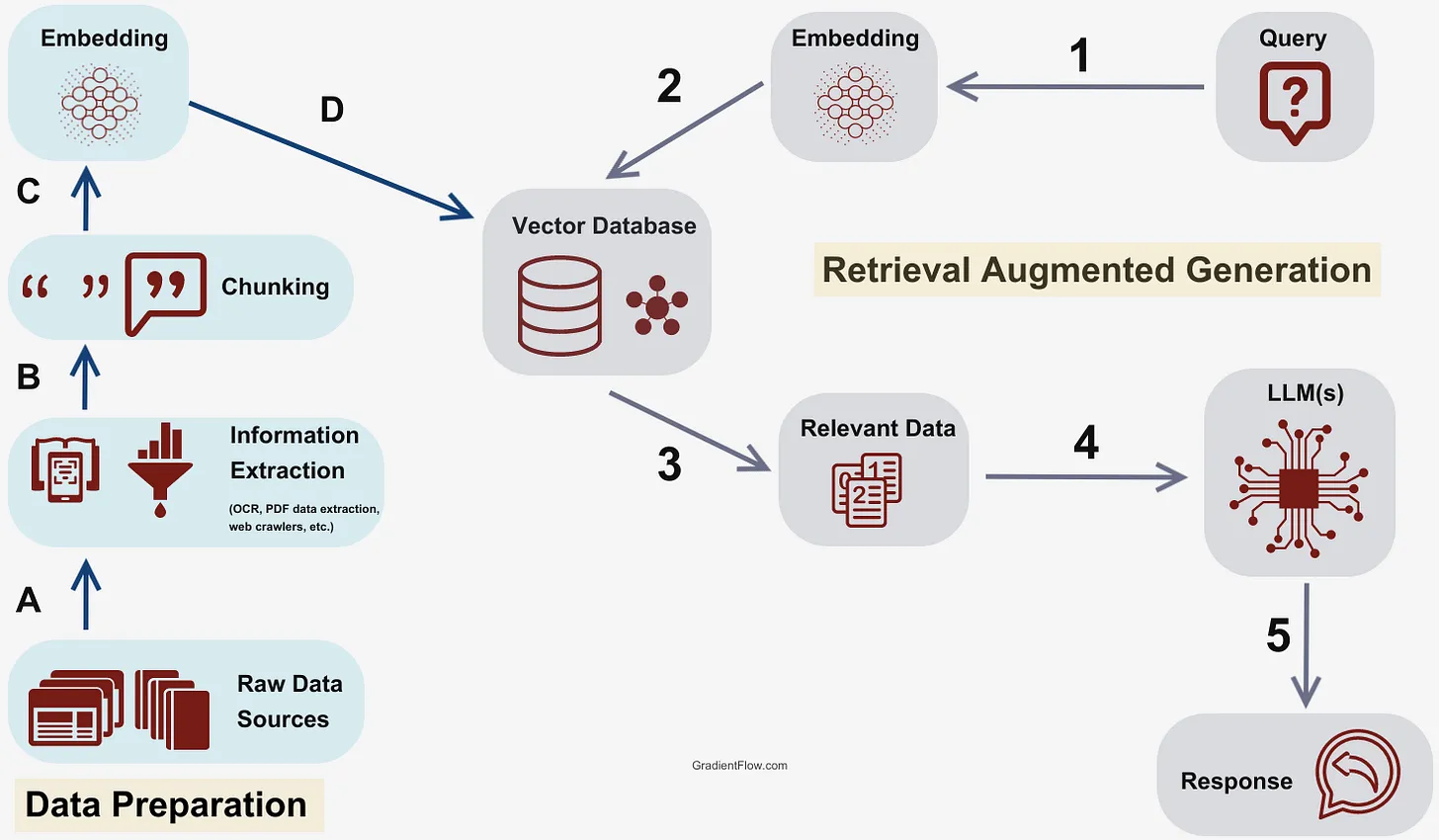
RAG 前的準備 - 資料前處理
資料準備
在進行 RAG 之前我們想必得先準備資料進行一些處理,以下介紹幾個步驟
- 原始資料來源 (Raw Data Source):
- 原始資料來源包含書本、網頁內容和 PDF 文件,還可能包括學術論文、新聞報導、社交媒體貼文、官方文件、技術文檔、視頻字幕和口述歷史記錄等等
- 資訊提取 (Information Extraction):
- 將於從各種類型的資料源中識別並提取有用資訊,資訊提取的過程可能涉及多種技術和方法,包括光學字元辨識(OCR)、PDF 載入、網頁爬蟲等等
- Chunk 拆分
- 為什麼需要拆分?
- 在檢索增強生成(Retrieval Augmented Generation, RAG)過程中,對文本進行 Chunk 的拆分一部分的原因是受到大型語言模型(LLM)的 token 限制,由於一次能夠處理的字數是有限的。因此將長文拆分成更小的單元(即 Chunk)成為一個解決方案。
- 試驗分割的數量
- 不同的 Chunk 拆分策略也影響效果。適當大小的 Chunk 能夠確保每一塊內容都在 LLM 的處理範圍內,同時保留足夠的上下文訊息,較大的 Chunk 大小可能有益,但超過某一點後效益會遞減,過多的 Context 可能會引入雜訊。而過小的 Chunk 則可能缺乏足夠的 Context 支撐準確生成。
- Overlap 設計
- 為了解決文字因為被分割成 Chunk 後導致不連貫的問題,因此 Chunk 之間的重疊(Overlap)設計是提升 RAG 的一個方法,透過在相鄰 Chunk 之間建立一定量的重疊,可以使得每個 Chunk 在被單獨送入 LLM 進行處理時,仍然能夠帶有來自其前後 Chunk 的 Context 資訊。
Embedding 到 vector database
在文字分割切成 Chunk 後就能進到先前提到的 Embeddings,這一個過程通常利用預訓練的自然語言處理(NLP)模型完成,如 BERT、GPT 等 (備註),這些模型能夠捕捉 Chunk 中的語義訊息,並將其映射到向量空間中。最後再自行存入已經準備好的向量資料庫中。
備註:他們可能提供(RESTful API),讓開發者能將資料發送到他們的 LLM 系統進行處理。這樣一來,使用者便可以獲得文字的嵌入向量表示。
Retrieval Augmented Generation 過程
準備好資料存到向量資料庫後接下來就遵照以下步驟來生成回應
- Query:RAG 過程的起點,使用者通過輸入一個問題或需求作為查詢。
- Embedding:將問題或需求先經過(Embedding),使得問題或需求的語義訊息將其轉換為向量
- Vector Database:Embedding 的向量接著被用來與 Vector Database 中的向量進行比較
- Relevant Data:透過演算法像是 K-NN、ANN 演算法的比較來與向量資料庫找到最相關的向量
- 檢索到的相關數據結合使用者的 prompt 被送入 LLM 當中。
- Response:最後 LLM 生成的使用者查詢的回應(Response)呈現給使用者觀看
圖片來源:Best Practices in Retrieval Augmented Generation